Some strategies employed to achive High Availability include:
Examples: E-mail, Web (WWW)
1a. Central Authentication (Kerberos servers, aka KDC's)
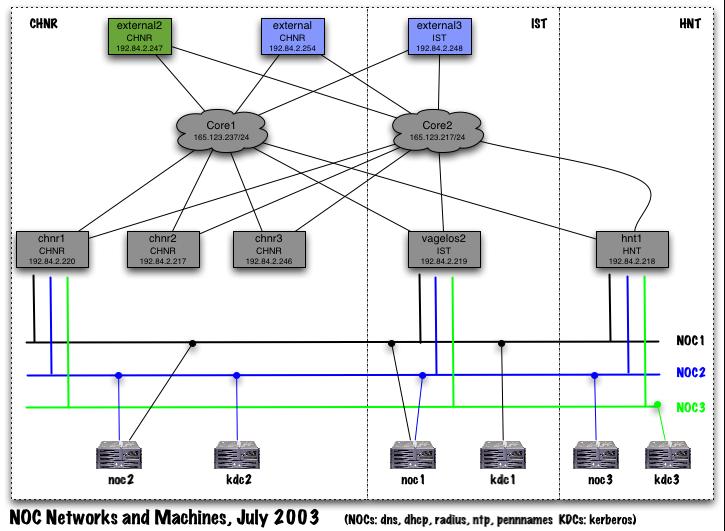
The Kerberos central authentication service runs on a set of three machines (kdc1, kdc2, kdc3). All are multiprocessor systems with internal storage redundancy via RAID. They support the Kerberos Authentication (AS) and Ticket Granting service (TGS). No other externally reachable services run on them. Each server is housed in a different machine room in a different campus building, on a different physical network which is in turn connected to a different campus core router. The Kerberos protocol supports multiple servers with automatic failover. Hence the authentication service continues to function even if any two of the servers are down or unreachable.
1b. Other core infrastructure services (RADIUS, DNS, DHCP, NTP, PennNames)
These services run on the set of three central infrastructure servers known as the "NOC" systems (NOC1, NOC2 and NOC3). All are multi- processor systems with internal storage redundancy via RAID. Each server is housed in a different machine room in a different campus building. For historical reasons, they are located on two different physical networks (instead of three different networks as in the case of the newer Kerberos servers). However a plan is in place to migrate the third NOC system onto a third network to further increase the level of redundancy and availability of these services. The DNS, RADIUS, DHCP and NTP services support automatic failover at the protocol level. The PennNames service is a homegrown service that doesn't yet support transparent failover. For this reason, loss of the primary NOC server necessitates a manual procedure by which a secondary NOC server additionally assumes the identity of the primary server. This manual reconfiguration process takes about 15 minutes of staff time.
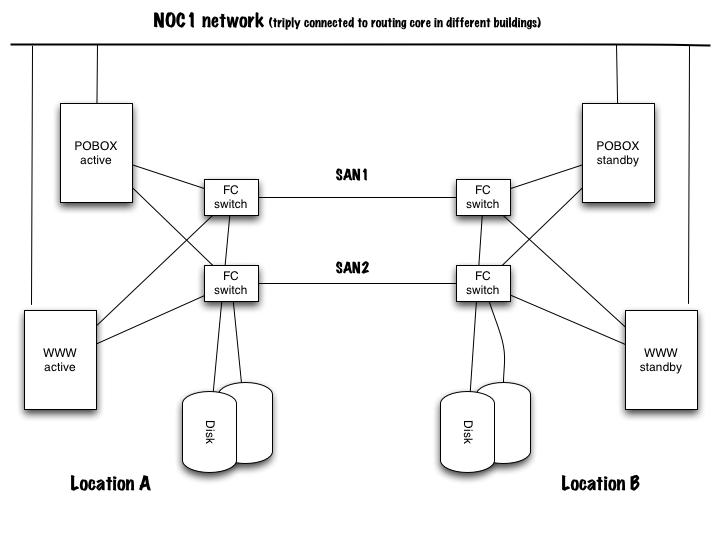
The E-mail and web service is designed in the following way: Each set of servers and associated storage is replicated at two sites. One of the sites houses the primary ("active") servers and the primary storage. The second site houses the set of standy servers and replicated storage. Data from the first site is replicated synchronously (in "real time") to the storage system at the second site. Two separate fibre channel storage area networks (SAN) interconnect the systems and storage. Each server has a separate link into each fibrechannel network and can reach the storage at either site. Additionally each storage system has internal redundancy via RAID. The servers are located on the primary infrastucture services network (the NOC1 network), which is triply connected via three different buildings to three distinct campus core routers.
In the event of a catastrophic failure of a server or storage system at either site, the system can be manually reconfigured by staff to use the alternate standy servers and/or the secondary storage. This procedure takes about half an hour.
It may be possible in the future to deploy a more advanced system that employs server and storage "clustering". This will enable continuous operation in the event of server/storage element failure. However, significant systems and software development and testing effort would need to happen first, to make sure all the applications can be made to operate in the clustered environment.